Introduction to Imprint¶
Welcome to Imprint!
What is Imprint?¶
Imprint is a framework for automating the generation of similarly-structured documents in MS Office Open XML format (docx). Its goal is to provide a robust, repeatable, and reliable system for generating complex content. It eliminates the issues associated with manually generating repeated content.
An example usage is hardware testing reports. The report for each component has an identical structure with all the other reports. However, the numbers, charts and tables have to be obtained from data sets specific to that hardware component.
How Does It Work?¶
Imprint is sturctured in a set of components arranged in layers between the user and the final document that it creates.
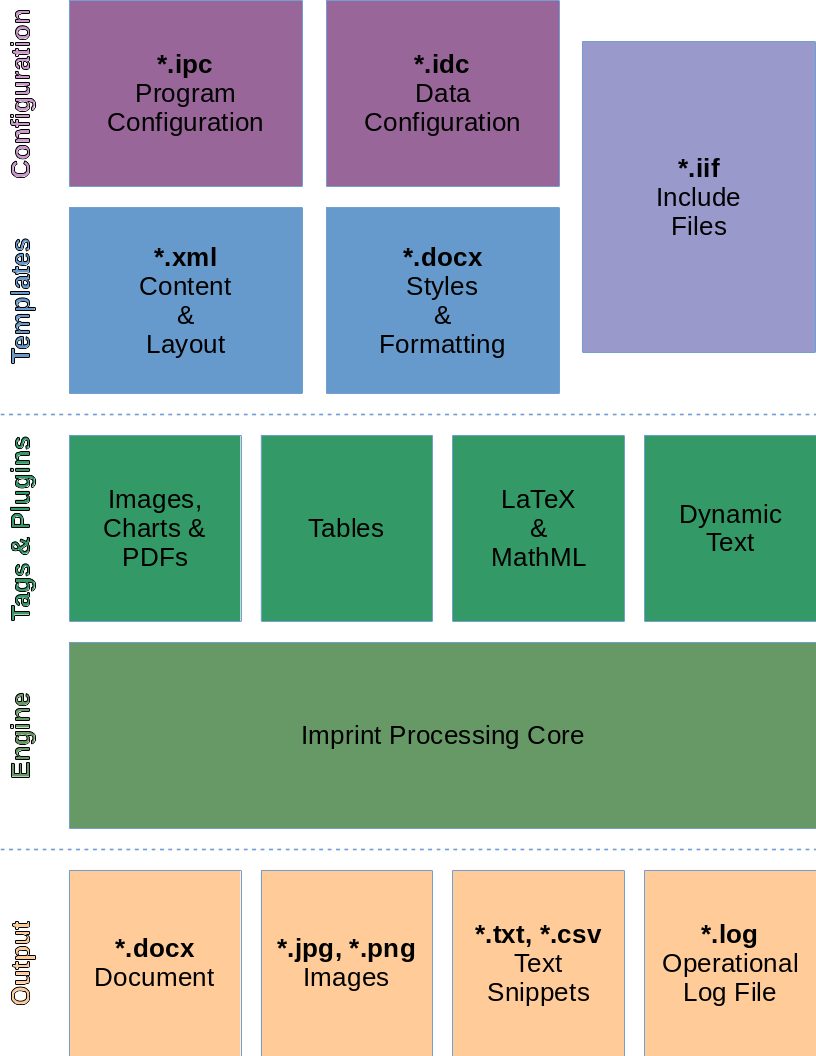
The components and layers of Imprint
Configuration Layer¶
The files in the configuration layer are provided for each report. They contain a distillation of all the differences between reports of a given type. IPC files configure the Engine Layer (the essence of Imprint itself). IDC files files direct the inputs and behavior of the Plugins Layer.
Templates Layer¶
Templates are static configuration files. The structure of the document, along with all static text and placeholders for generated content is laid out in the XML Template file. The styles referenced in the XML are defined in an empty Word document, the DOCX Stub.
The IIF Files files serve as a bridge between the Configuration Layer and the Templates Layer. They follow a similar keyword definition format to the configuration, but provide static content that is intended to be shared between reports. Include files are used to clean up redundancy in the Configuration Layer by aggregating static information[1].
Plugins Layer¶
Content-generation plugins are written to handle the data-specific content of complex tags dynamically. A well written plugin can be used across multiple document types in an organization. Plugins can generate images, tables and text with values that depend in a dynamic configuration. The type of content a plugin generates, and the interface it follows, is determined by the tag that it supports.
Concretely, plugins are Python classes (or functions) that implement the exact interface laid out by their parent tag (see Plugin API). An introduction to writing plugins is provided in the Writing Plugins tutorial. Live examples can be found throughout any Imprint deployment.
The input data and plugin behavior is defined by an IDC File in the Configuration Layer, so the same plugin can be used to generate all sorts of content based on different configurations. For example, hardware reports will generally contain tables of statistics and some sort of chart or histogram to accompany them. Having both of those plugins share data loading and preprocessing code (and usually their data configuration dictionary as well) guaranteeds consistent results.
Engine Layer¶
The engine is the core of Imprint that runs the entire system. It is responsible for setting up the runtime environments, ingesting all the configuration and directing the operation of all the plugins. The engine is executed through entry points in the Programs.
Output Layer¶
The final layer is the output. In addition to the main document, Imprint provides an enormous amount of traceability with its Logging output. The log file itself can be set up through IPC File. Both the name and the logging level are configurable. In addition to the log, all images that are generated for insertion into the document can be stored in separate files as well. This option is also configurable through the IPC File.
Historical Note¶
How did imprint come into being?
Around the years 2016-2018, the analysts at the Detector Characterization Lab (DCL) at NASA Goddard Space Flight Center (GSFC) working on Euclid project were creating reports of all the flight-grade SCAs[2] and SCSs[4]. These reports were on the order of around 50 pages each, contained figures and tables describing the analysis of every aspect of the testing being done on each component, and written individually by hand. Usually, the analysts would of course start with an existing report as a template, and modify the pictures, numbers and tables based on their results.
This presented a number of issues, all of which could be solved with automation. The size of the report, and the amount of data each one contained made replacing items both time consuming and error prone. This was exacerbated by the fact that the same data was used to generate multiple sets of figures, tables and text elements within a given document. And of course the number of reports being generated made it difficult to keep track of versions and templates. For one thing, it was easy to forget to update one of the figures or tables but not the other. For another, any typos that were found and corrected in the static text of the document would not always find their back to all the existing versions, and therefore possibly not into future ones either.
The reports were being used for two purposes. The long-term purpose would be to archive the detector data, so that all the test data would be available for in-flight debugging teams. In the short-term, the reports were used to communicate test results to the the customer, The European Space Agency (ESA). With this set of goals, having minor but persistent errors in the documents was deemed unacceptable, as was the amount of time being spent by qualified analysts in editing Microsoft Word documents.
A program called RepGen was created to solve most of the issues encountered with the generation of such reports. Its primary requirements were to be robust, accurate, reliable, repeatable and traceable. It placed all of the static text into an XML template making it trivial to fix typos across all reports and revisions at once. The configuration files for a particular report were structured to eliminate redundancy of information, improving traceability. Shared include files, along with a sensible structure of data was used to turn the creation of new configurations into a two-step copy-and-paste job. The content generation code was technically left up to the group using RepGen. However, code reuse was encouraged here as well, and certainly built into the basic handlers, so that consistent results could be expected from a single dataset used in multiple types of content. Plugins allowed similar types of information about different data sets to be rendered in a consistent format in multiple places in a report. All operations were logged to any level desired, including the generation of all content, so errors and inconsistencies could be found quickly and easily.
RepGen went on to become Electronic New Technology Report (eNTR) #1518805444 at NASA. Imprint is a philosophical child of RepGen. It does not share any of the old code, but it does provide a significantly improved version of the same sort of flexibility as its inspiration.
Where do I go From Here?¶
If you are a new user of Imprint, the recommended place to start is the Tutorials section. The Getting Started page especially will help you get a sense of how to set up an Imprint project for the first time.
The other main area of the documentation, Reference is for more advanced users. It contains the formal definitions and specifications of the interfaces used by the system.
If you are unsure where to go next, the Main Page is always a good place to start browsing through all of the available topics.
Footnotes
| [1] | The <expr> tag provides a more limited way to do this as well. |
| [2] | (1, 2) The Sensor Chip Array (SCA) is basically the detector chip. |
| [3] | Sensor Chip Electronics (SCE) is the ASIC used to operate the detector. |
| [4] | The Sensor Chip System (SCS) is the SCA[2] combined with the SCE[3]. |